时间: 2024-06-10 17:39:17 | 作者: 交通产品系列
开发的运用。谷歌在2014年敞开了TPUv1的项目,15个月后,全新的TPU硬件就现已运用到了谷歌的数据中心里,连带架构、编译器、测验和布置都悉数更新了一遍。
那时GPU在推理这块的功能也仍是超越CPU的,但TPU的呈现改变了这个格式。与其时英特尔的Haswell CPU比较,TPUv1的能耗比有了80倍的提高,相较其时的sla K80 GPU,其能耗比也高达它的30倍。
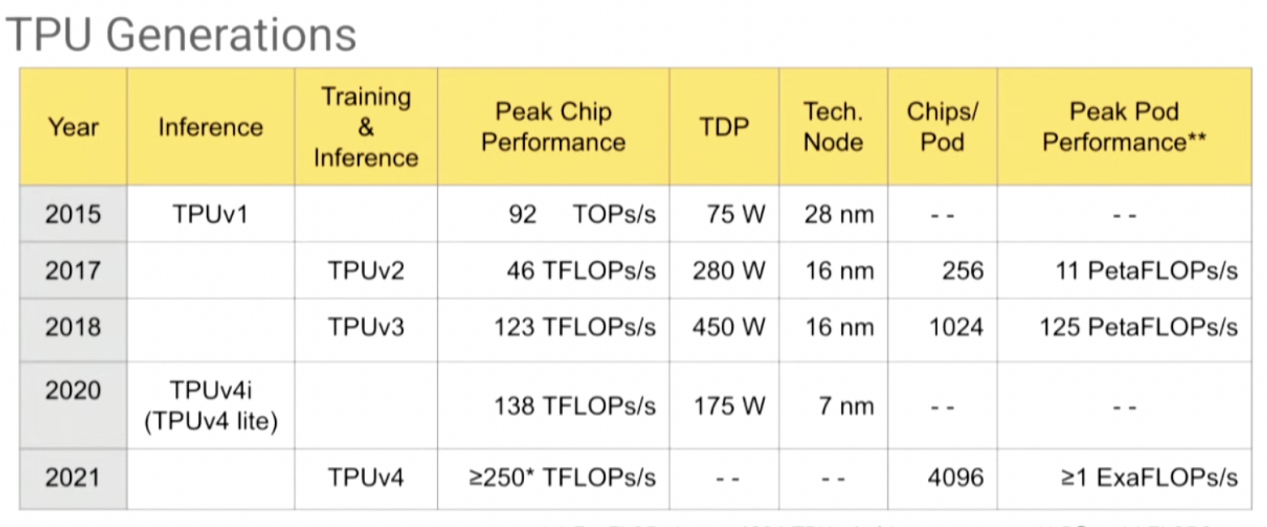
谷歌此举引爆了整个商场,咱们发现了还有除了CPU、GPU之外的计划。英特尔发觉后也收买了一系列深度学习DSA,比方Nervana、Movidius、Mobileye和Habana。谷歌在云服务上的竞赛对手们,阿里巴巴和亚马逊也开端打造自己的推理、练习芯片。能耗比之战下,咱们很快也意识到机器学习带来的碳脚印成了下一个急需解决的问题。
依据上一年在IEEE Spectrum上发布的《深度学习获益递减》一文中说到,跟着机器学习的开展,到了2025年,最强的深度学习体系在ImageNet数据会集进行物体辨认时,错误率最高只要5%。但练习这样一个体系所需求的算力和能耗都是巨大的,更糟糕的是,其排放的二氧化碳将是纽约市一整个月的排放量。
机器学习的碳排放能够被分为两种,一种是运营排放,也便是数据中心在运转机器学习硬件中发生的碳排放;第二种是整个生命周期内的排放,不只包括运营排放,还包括了一切的环节的碳排放,比方芯片制作、数据中心制作等等。考虑到后者触及更为杂乱的研讨,所以大部分碳脚印的研讨都会集在运营排放上。
至于怎么记载碳排放,这也很简略,只需求将练习/推理的时长x处理器数量x每个处理器的均匀功耗x PUE x 每千瓦时的二氧化碳排放即可。除了最终一项参数需求从数据中心那获取外,其他的数据根本都是揭露,或取决于机器学习研讨者自己的挑选。
图灵奖得主、谷歌出色工程师David Patterson教授对现有的机器学习的研讨和作业提出了以下几点主张。首要,从模型开端着手,机器学习研讨者需求继续开发功率更加高的模型,比方谷歌上一年发布的GLaM通用稀少言语模型,相较GPT-3,它多出了7倍的参数,在自然言语推理等使命上都要优于GPT-3。但相同重要的是它的能耗和碳脚印方针,依据谷歌发布的数据,与运用V100的GPT-3比较,运用TPUv4的GLaM二氧化碳排放减少了14倍,可见模型关于碳脚印的影响。其次,在发布新模型的时分,他主张也把能耗和碳脚印这样的数据揭露,这样有助于促进机器学习模型在质量上的良性竞赛。
接着是硬件,他指出咱们应该像TPUv4或许A100 GPU等,这类机器学习能效比更高的硬件。其实这一点反倒是最不需求忧虑的,这几乎是每个草创AI芯片公司都在测验的做法,即便在峰值上不敌这些硬件,也肯定会在能效比上尽可能做大极致。

还有便是常见的能效衡量方针PUE,大型机器学习负载往往要在数据中心上运转,而要让数据中心的PUE挨近1并不是一件简略的事。依据Uptime Institute的计算,各家厂商旗下最大数据中心的年度PUE为1.57,就连我国工信部印发的《新式数据中心开展三年行动计划(2021-2023)》中提出的最终方针也只是将新建大型数据中心PUE下降至1.3以下。但好在新建的数据中心往往都不会只满足于这个方针,而是往1.1甚至1.06这样的方针推动。
可这个方针并不是一个死数据,跟着负载和用量的变化,PUE是在继续动摇的,不少数据中心只是在建成时发布了能效方针,之后就再未发布过任何数据了。在这块做得最好的也仍是谷歌,谷歌年年都会发布年度能效陈述,将各个数据中心每个季度的PUE发布出来。
不过只是只要极低的PUE只能体现出高能耗比,David Patterson教授以为还必须同时发布每个区域数据中心的清洁动力占比。比方阿里巴巴初次发布的《2022阿里巴巴环境、社会和管理陈述》中就说到了2021年,阿里巴巴在中国企业可再次出产的动力购买者中排名榜首,2022财年阿里云21.6%的电力来自清洁动力。
在双碳方针的提出下,我国其完成已执行到了机器学习的硬件上,但在软件和碳脚印透明度这方面还有能改进的空间。机器学习要想做到耗费更低的算力来完成更优的作用,就必须从一切的环节做到节能减排。
